
Доказательная медицина может стать важным направлением исследований для объективной разработки действительно эффективных методов лечения и диагностики. В настоящее время, однако, данная область в значительной степени захвачена опытными манипуляторами общественным сознанием. Что значит “в значительной степени”? Каким образом “захвачена”? Какие есть для этого доказательства? Исследование в стиле “большие данные” (массив 20 млн англоязычных публикаций), проведенное на основе топологической теории распознавания, позволило получить ответы на эти и многие другие вопросы [1].
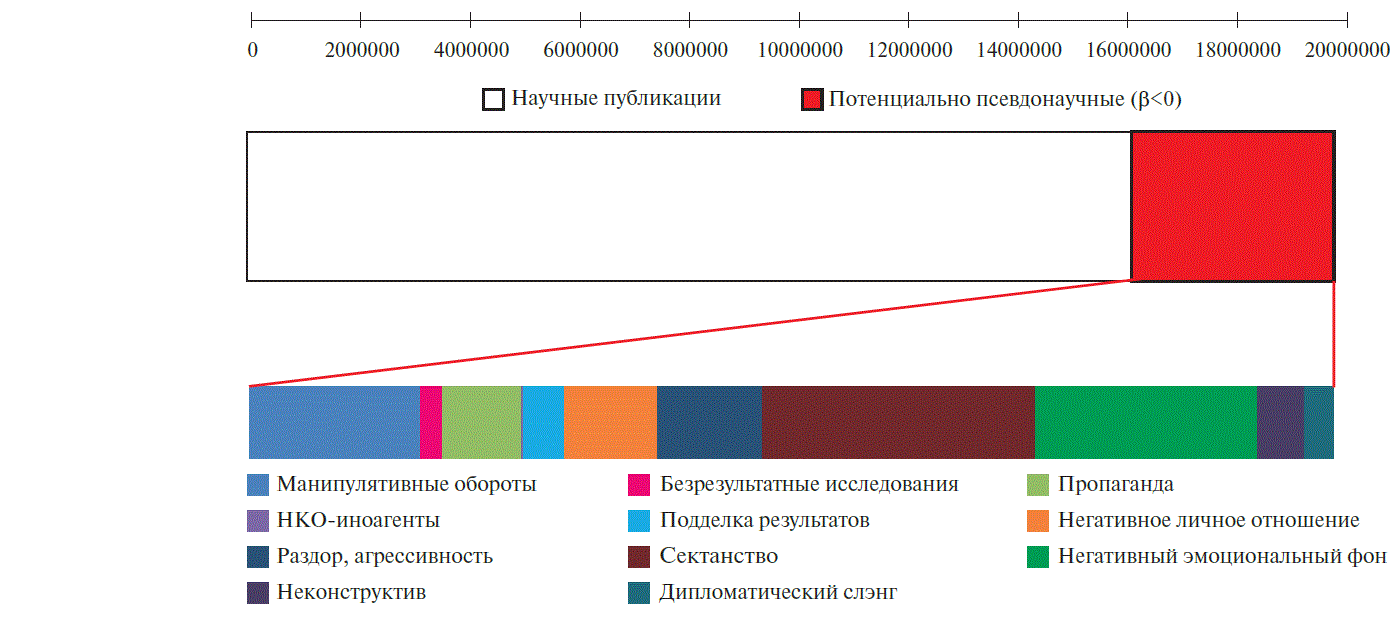
В работе [1] каждое из 20 млн исследований оценивалось по комплексной шкале (т.н. β–балл), включающей данные по 16 классам эмоционально-нагруженных конструкций английского языка: манипулятивные обороты речи, исследования без положительных результатов, пропаганда, подделка результатов, негативное личное отношение, агрессивность текста, негативный эмоциональный фон и др. Значение бета-балла меньше нуля соответствует преобладанию манипулятивного языкового фона над содержательным.
Оказалось, что почти 4 млн (точнее, 3.68 млн) из 20 млн публикаций в базе данных PUBMED содержат чёткие следы эмоциональной манипуляции (β–балл<0). Напомним, что PUBMED – это не сайт блоггеров, не желтая пресса, а база данных, содержащая НАУЧНЫЕ публикации из журналов, которые зарегистрированы одновременно в ресурсах SCOPUS и WEB-OF-SCIENCE. При таком жестком отборе публикаций в PUBMED очень странно наблюдать, что 20% из этих публикаций, оказывается, занимаются манипуляцией сознанием на примитивном уровне англоязычной жёлтой прессы…
Еще более интересным фактом является тот, что эти манипуляции сосредоточены в достаточно узком круге тематических рубрик базы данных PUBMED – 3520 из 27840 рубрик. Манипулятивная англоязычная лексика наиболее распространена в публикациях в разделах «экономика» и «юриспруденция» (что, вообщем-то, неудивительно и даже вполне ожидаемо).
Весьма манипулятивными, однако, оказались и данные по медицинской статистике западных стран (β=–6,41), в т. ч. рассматривающие вопросы стоимости лекарств (β=–3,86), перспективы т. н. «планирования семьи» (β=–3,61), легализацию эвтаназии (β=–1,53) и т. п. (см. многие другие примеры в тексте статьи [1]). Чрезвычайно интересно отметить, что даже в случае статей из чисто публицистических изданий, каким-то образом попавших в PubMed (например, «Нью Йорк Таймс», рубрика «SO – N Y Times Web»), среднее значение β-балла было намного выше (β=–0,64), чем в случае отдельных якобы «научных» журналов (см примеры в [1]).
Наиболее неожиданной оказалась резко отрицательная динамика бета-балла для рубрик PubMed, имеющих непосредственное отношение к доказательной медицине. Например, до 2008 г. β-балл публикаций под такими рубриками колебался вблизи вполне приемлемых значений: +1,5…+2,2. После 2008 г. началось постоянное снижение значений β-балла, так что в 2013 г. средний β-балл публикаций в таких рубриках приобрел отрицательное значение. После 2013 г. началось ещё более стремительное падение значений β-балла (на 5,1 балла/год), так что к концу 2019 г. среднее значение β-балла составило –32,0. Столь резкое возрастание эмоциональной нагруженности публикаций по доказательной медицине за последние шесть лет полностью соответствуют концепции «рейдерского захвата доказательной медицины» (англ. hijack) т. н. «пиратами доказательности» [2].
И, наконец, наибольшими положительными значениями β-балла, т.е. наименьшей степенью эмоциональной манипуляции, отличались публикации по спортивной медицине, системной биологии и нутрициологии, биофизике, математическим методам в биологии и медицине, в т. ч. математическим методам «искусственного интеллекта» и «машинного обучения» [1]. Таким образом, сентимент-анализ значительной части от всех имеющихся научных публикаций по биомедицине дает обильную пищу о размышлениях относительно науки, псевдонауки и лженауки…
Источник: ANTIFAKE.
Более подробная информация о результатах данного исследования представлена на сайте antifake-news.ru
В подавляющем большинстве клинических исследований, публикуемых в высокоцитируемых реферируемых журналах, отмечается крайний примитивизм. И это несмотря на чрезвычайную сложность данных реальных биомедицинских исследований – от тысяч до миллионов разнородных признаковых описаний, десятки-сотни тысяч пациентов.
Тем не менее, вместо комплексного, in-depth, интеллектуального анализа данных, публикуемые результаты исследований чрезвычайно загрублены: из всего массива закономерностей (сотни тысяч) выделяются, как правило, 1-2 (т. н. «первичная точка исследования», англ. primary outcome), которые почему-то «особо интересны» для исследователя (как правило, вследствие интересов коммерческого плана), и анализируется их статистическая значимость обычными методами математической статистики. Остальные корреляции просто игнорируются как «не имеющие интереса».
Важными научно-техническими причинами столь безответственного отношения к анализу интересных и сложных биомедицинских данных является (1) нежелание использовать методы комплексного анализа сложных разнородных данных, (2) густопсовое невежество относительно таких методов и (3) обсессивно-компульсивное использование уже имеющихся статистических эвристик, выбранных произвольно просто из соображений «удобства». В случае анализа сверхбольших данных, такого рода “подход” абсолютно неприемлем, особенно если идёт речь о т.н. «доказательной медицине».
Математической основой для разработки новейших подходов к анализу сверхбольших данных являются:

Фармакоинформационный подход к разработке перспективных препаратов, к оценке эффектов имеющихся лекарственных препаратов подразумевает использование методов интеллектуального анализа разнородных биомедицинских данных, методов молекулярной фармакологии и биоинформатики, хемоинформатики, анализ сверхбольших массивов биомедицинских публикаций, разработку эффективных методов обработки сверхбольших массивов данных, получаемых в результате исследования живых систем современными высокопроизводительными (high-throughput) методами и др. В Институте фармакоинформатики при ФИЦ ИУ РАН разрабатываются, апробируются и практически применяются методы и алгоритмы анализа «сверхбольших данных» из области биомедицины и фармакологии.